_edited_edited.png)
In Todays world, Data is so much important for the so many organization like Healthcare, software industry where that data can be used for future study and evaluation purpose. As we know the internet holds a pool of data. But some websites may not allow to download and save the data. These days data is used by e-commerce where data is used to compare across multiple platform, technology where data is used for reading the gesture and manipulate in order to bring an AI to use for daily routines. HealthCare industry where according to patients condition suggesting food to eat or providing that small window to patients it helps reduce the amount of physical work an so on...
WebScraping is an automated process where a large amount of data is collected from the websites. Selenium comes in picture when dealing with web scraping. Selenium is an open source tool. Selenium is used for automation test purpose where it performs all those user interactions with web elements like filling the form, clicking, navigating through pages can be done by selenium web driver. Till now you get an idea about what role played by the selenium.
Selenium web scraping is extraction of huge scale data from the webpage and storing it in to the database. This large scale data then be used for manipulation, analysis in order to innovate new things. The Data Analytics which then access data which is stored in database. What so ever data we extracted can be the raw data which is then by applying different filtering strategies we can manipulate and store according to our need for the project.
Pre-requisite :
Java
Selenium
Postgres
Lets have an example of Book Store from this website https://demoqa.com/books for this create a simple maven project and add the required dependancies for selenium-java, webdrivermanager, postgresql, lombok in pom.xml
Tips: You can get these dependancies from maven central repository https://mvnrepository.com/artifact
Create a class BookPojo. Using lombok, you can provide the field names and just mention @Data which provide getters and setters.
@Data
public class BookPojo {
String Title;
String Author;
String Publisher;
}Creating a database connection is the crucial step for storing data into database. Lets have one BookDatabaseOperations.java class where getconn(), closeConn(Connection conn), createTable(), insertProduct(BookPojo bookVo). for this you can refer my previous blog which provides details on how to connect to database, how to close connection both methods are same so refer this https://www.numpyninja.com/post/creating-restful-api-using-spring-boot-framework
Tip:change the database name according to your database.
now create a table for Book Store with the fields Book Title,Book Author,Book publisher etc.
public void createTable() throws Exception
{
try {
String createTableBookquery="CREATE TABLE public.Books (Title text,Author text,Publisher text);";
PreparedStatement ps = null;
ps = getConn().prepareStatement(createTableBookquery);
ps.execute();
System.out.println("Table Created...");
} catch (Exception e) {
e.printStackTrace();
}
}Now by scraping whatever data we collected using selenium script that we have to insert in to the database.
So write code for insert book details.
public void insertBook(BookPojo bookVo) {
try {
PreparedStatement ps = null;
String insertBook = "INSERT INTO public.Books (Title,Author,Publisher)"+ "VALUES (?, ?, ?);";
ps = getConn().prepareStatement(insertBook);
int columnCounter=1;
ps.setString(columnCounter++, bookVo.getTitle());
ps.setString(columnCounter++, bookVo.getAuthor());
ps.setString(columnCounter++, bookVo.getPublisher());
ps.executeUpdate();
}catch(Exception e) {
e.printStackTrace();
}
}A main class where instantiate an driver and add implicit wait
WebDriver driver;
FirefoxOptions firefoxOptions = new FirefoxOptions();
driver = new FirefoxDriver(firefoxOptions); driver.manage().timeouts().implicitlyWait(Duration.ofMinutes(2)); now provide the url
driver.get("https://demoqa.com/books");this is how we are seeing books on this link

Here we are looking for only JavaScript books so with sendkeys we can enter the text in textbox.
WebElement searchbox = driver.findElement(By.xpath("//input[@id='searchBox']"));
searchbox.sendKeys("JavaScript");for the search provide locator for search and after click, there are four JavaScript Books.
driver.findElement(By.xpath("//span[@id='basic-addon2']")).click(); we are having this on the screen after search
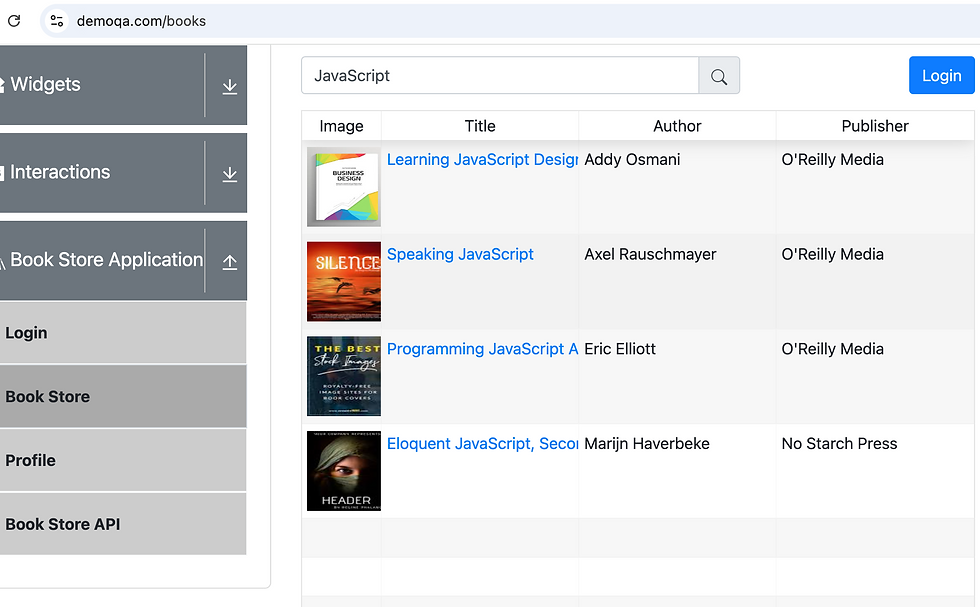
and then we are creating a table and call for a method which returns the book information that is extracted such as title , author , publisher And finally added to the database by using insert query.
try {
dbops.createTable();
} catch (Exception e) {
}
List<BookPojo> allBooks=Library.getBookList(driver);
System.out.println(allBooks.size());
for(BookPojo singleBook :allBooks)
{
if(singleBook!=null)
dbops.insertBook(singleBook);
}Now coming to data extraction, let's see how we are extracting and storing the data. This is the DOM structure with N no of div rows, each div row representing one book. build xpath dynamically to iterate over rows.

public static List<BookPojo> getBookList(WebDriver driver)
{
String title;
String author;
String publisher;
List<BookPojo> out=new ArrayList<BookPojo>();
driver.manage().timeouts().implicitlyWait(Duration.ofSeconds(5));
//get the row count
int rows = driver.findElements(By.xpath("//div[@role='rowgroup']")).size();
for(int row = 1; row<=rows; row++)
{
BookPojo singleBookOutput=new BookPojo();
//Extract title,author,publisher and returning that object
title=driver.findElement(By.xpath("//div[@class='rttable']//div[@class='rt-tbody']/div["+row+"]/div/div[2]")).getText();
//If my title is null we don't need to add it to database
if(title==null||title.trim().isEmpty())
continue;
author= driver.findElement(By.xpath("//div[@class='rt-table']//div[@class='rt-tbody']/div["+row+"]/div/div[3]")).getText();
publisher= driver.findElement(By.xpath("//div[@class='rt-table']//div[@class='rt-tbody']/div["+row+"]/div/div[4]")).getText();
System.out.println("extracted data--> "+title+" - "+author+ " - "+publisher);
singleBookOutput.setTitle(title);
singleBookOutput.setPublisher(publisher);
singleBookOutput.setAuthor(author);
out.add(singleBookOutput);
}
return out;
}This is how extracted data gets stored in database.

Conclusion : With the help of Webscraping we can store the raw data which is used in many ways for Study, Compare, Innovation and so on... So, the possibilities are endless ...
Thank you... For Reading my blog. Learning is fun!