_edited_edited.png)
What is Web scraping?
Web scraping is the automatic process of extracting information from a website. Most of this data is unstructured in an HTML format which is then converted into a structured data in a spreadsheet or a database so that it can be used for other applications. There are several ways to scrape data from websites which include using different tools, particular APIs or even writing your own code for web scraping from scratch.
[Disclaimer: Before beginning, many websites can restrict scraping of data from their pages. How do you know which websites are allowed or not? You can look at the ‘robots.txt’ file of the website. You can simply put robots.txt after the URL that you want to scrape, and you will find the information on whether the website host allows you to scrape the website. The data I have scraped is purely for learning purpose]
For this project, I was looking to scrape job postings from Indeed using selenium and Java. When I looked up online, I saw that most of them were done using python and could not find enough resources using selenium and Java. This blog is for all those who are looking to scrape data using selenium-Java.
The challenging part here is identifying the elements in the DOM structure using the different locators. My suggestion would be to use your own customized xpath/css locators instead of relying on the browser tools as it does not work all the time.
We can use the id, name, className, tagName, linkText, partialLinkText wherever applicable else use the customized xpath/css locators. There are several ways to define xpath and CSS locators.
Syntax for xpath
//tagname[@attribute=’value’] For e.g., //input[@class=’xyz’]
//*[@attribute=’value’]
//tagname[contains(@attribute,’value’)]
Syntax for CSS
tagname[attribute=’value’]
tagname#id
tagname.classname
tagname#attribute
There are several other ways to define xpath using the parent child relationship or traversing all the way from the root and identifying the elements as well.
Pre-requisites
Before we get started, the following should be installed in the system:
Java
Maven
An IDE (here I have used eclipse)
Here we are using Maven to manage our project in terms of generation, packaging, and dependency management. Maven is a POM (project object model) based build automation and project management tool. Maven is widely used for dependency management in Java. It also provides a predefined folder structure to write the code. We can add different plugins and JARs in our project.
Ensure the POM file has all the required dependencies (testng, selenium-java, selenium-chrome-driver, selenium-support, selenium-api, selenium-server, poi-ooxml, poi-ooxml-schemas)
The following steps is specific to scrape job data from indeed. This could be refined as per the requirement.
Steps to scrape job data from indeed
1. Create a testng class under the respective package in the Maven project. Launch the browser and navigate to the URL (indeed.com).
2. Key in the required job postings and hit on search.
3. Use the pagination logic to traverse through the different pages and get the job details from the job cards.
4. Inspect the required elements and get the data.
5. Write the scraped data into a spreadsheet.
Step 1: After creating the class, launch the browser and navigate to the URL
@BeforeTestpublic void beforeTest() {
System.setProperty("webdriver.chrome.driver","C:\\Users\*******\\Drivers\\chromedriver.exe");
driver = new ChromeDriver();
driver.navigate().to("https://www.indeed.com/");
driver.manage().window().maximize();
}Step 2: In my script, user input is prompted to look for the job postings for which we are looking to scrape the details. Here I have used the Scanner class for prompting the input.
// Create a Scanner object to prompt for user input
Scanner myObj = new Scanner(System.in);
System.out.println("What jobs are you looking for ? ");
job_Search = myObj.nextLine();
driver.findElement(By.id("text-input-what")).sendKeys(job_Search);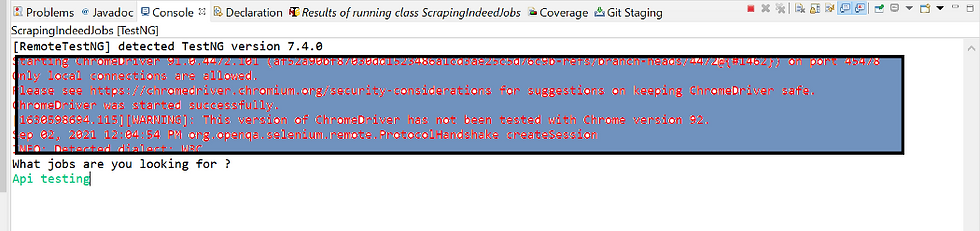
For e.g., Looking for Api testing related jobs

Input provided visible in the automated browser
Step 3: Traversing through the pages(using loop) and getting the job details from the job cards.
List<WebElement> pagination = driver.findElements(By.xpath("//ul[@class='pagination-list']/li"));
int pgSize = pagination.size();
for (int j = 1; j < pgSize; j++) {
Thread.sleep(1000);
WebElement pagei = driver.findElement(By.xpath("(//ul[@class='pagination-list']/li)[" + j + "]"));
pagei.click();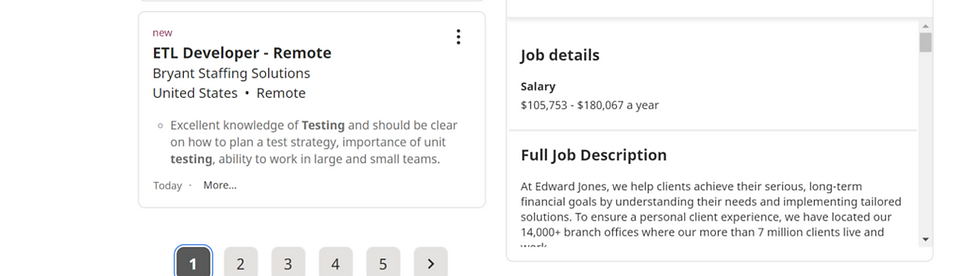
page 1
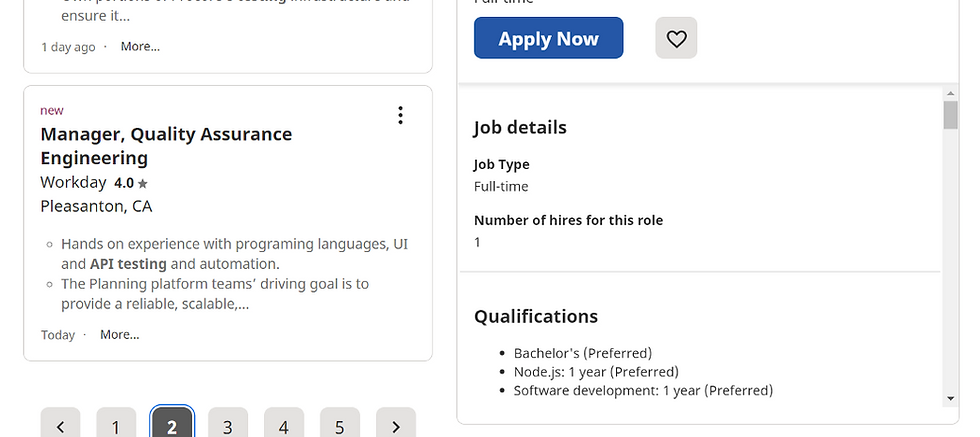
page 2 and goes on
Step 4: Inspecting the elements and getting the job card details. This is the challenging part, inspecting and finding the elements using the right locators is the key to get the required correct data. And we need to loop through the different job cards to obtain the required details. Here for example to look for job title, company name and location can be done as follows
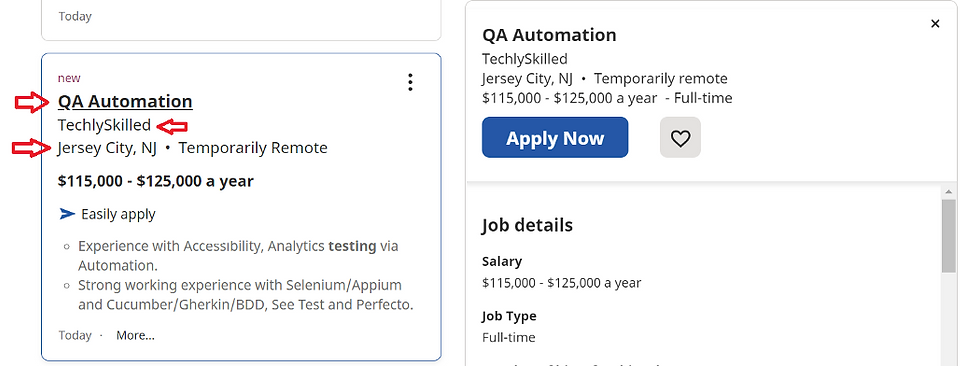
WebElement jobCard = driver.findElement(By.id("mosaic-provider-jobcards"));
List<WebElement> jobCardWitha = jobCard.findElements(By.tagName("a"));
int totcount = jobCardWitha.size();
for (int i = 0; i < totcount; i++) {IndeedJob iJob = new IndeedJob();//To get job title
List<WebElement> jobTitle = driver.findElements(By.xpath("//h2[@class='jobTitle jobTitle-color-purple jobTitle-newJob']/span"));
System.out.println("Job Title : " + jobTitle.get(i).getText());
iJob.setJobTitle(jobTitle.get(i).getText().replace(",", " ").replace("\n", " "));//To get Company name
List<WebElement> jobCompName = driver.findElements(By.xpath("//span[@class='companyName']"));
System.out.println("Job Company Name : "+jobCompName.get(i).getText());
iJob.setJobCompName(jobCompName.get(i).getText().replace(",", " ").replace("\n", " "));//To get Company location
List<WebElement> jobLocation = driver.findElements(By.xpath("//div[@class='companyLocation']"));
System.out.println("Job Location : " + jobLocation.get(i).getText());
iJob.setJobLocation(jobLocation.get(i).getText().replace(",", " ").replace("\n", " "));Step 5: All the job details are stored in an object using the setter and getter methods. Here I used FileWriter class and append() method to write the fetched details into a CSV
FileWriter csvWriter = new FileWriter(job_Search.replace(" ","")+".csv");
csvWriter.append("JobTitle");
csvWriter.append(",");
csvWriter.append("JobCompanyName");
csvWriter.append(",");
csvWriter.append("JobLocation");
csvWriter.append(",");csvWriter.append(iJob.toString());
csvWriter.append("\n");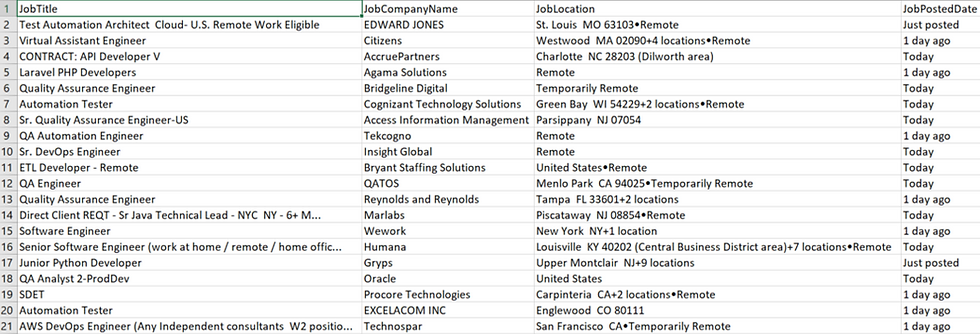
Fetched job details in a CSV
Following the above steps, I was able to scrape approximately 70 jobs in less than a minute. This was simple and straightforward method.
Hope this blog was a useful one. Happy scraping!!!