_edited_edited.png)
We live in a data-driven world, where a large amount of data is generated by every digital process, system, gadget, and sensor around us. We depend on these data to make decisions. But how do we get these data to analyze and get insights from it? Web scraping is the answer to it.
Web scraping is the process of automatically extracting large amounts of data from websites more efficiently and effectively. Data from the websites are usually unstructured. Web scraping helps collect unstructured data and store it in a structured form. There are different ways to scrape websites such as APIs, Data Extraction Services, or writing your own code. In this article, we’ll see how to implement web scraping with python.
The process of web scraping usually involves sending a request to a website and then parsing the HTML content of the response to extract the desired data. The parsed data then can be stored in a structured format such as a CSV file, excel file, or database for further analysis. The commonly used python libraries for web scraping are BeautifulSoup, pandas, and requests.
BeautifulSoup allows us to parse and extract data from HTML and XML documents in a simple and intuitive way. The library provides a set of tools and methods that allow searching for specific tags, attributes, or text and then extracting or manipulating the data as needed.
Pandas is a popular open-source data analysis library for Python used for data manipulation and analysis. It provides easy-to-use data structures such as Series and DataFrame and a high-level interface for working with structured data, such as CSV or Excel files.
Requests is a Python module that we can use to send all kinds of HTTP requests. It is an easy-to-use library with a lot of features ranging from passing parameters in URLs to sending custom headers and SSL Verification.
How does web scraping work?
Let's understand the web scraping process through a simple example. The steps included in the process are,
Find the URL that we want to scrape: Here I choose to extract the list of largest banks in the United States from the Wikipedia page.
Inspect the page to get the source code: Once we are on the page right click and select "inspect" to get into the source code as seen in Figure-1.
Find the data we want to extract: Here we need to find which tag contains our information. Using these tags, our main scraping libraries can target and parse information effectively throughout the scraping process.
Write the python code: I have used Jupiter notebook for coding. You can read the code in Figure- 2 and the explanation of each code below that.
Run the code and Extract the data: After running the python code, Using the pandas library we can create a data frame in which the data is stored
Store the data in a CSV file: Export the scraped data into a CSV file.
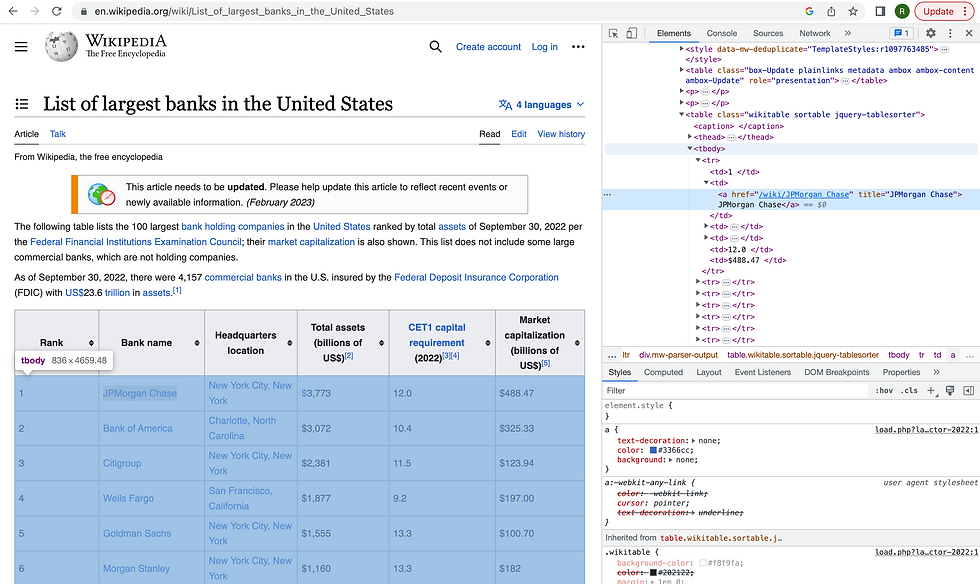
Figure-1: Source code of Wikipedia page
Now let's try to understand the python code we used to scrape the data, which is shown below in Figure-2.
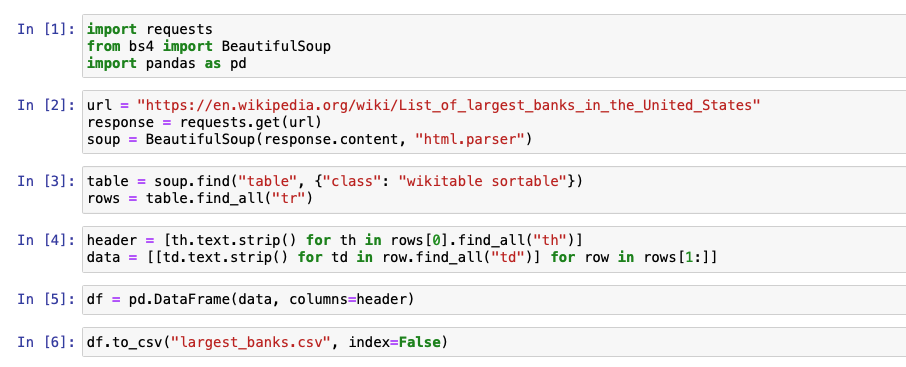
Figure-2: Python code
In [1]: Here we have imported all the necessary libraries:
requests for making HTTP requests.
BeautifulSoup for parsing HTML content.
pandas for creating a DataFrame to store the extracted data.
In [2]: The line of code "response = requests. get(url)" uses the Python requests library to send an HTTP GET request to the specified URL and assigns the resulting response object to the variable named "response". Next, we are using the "html.parser" parser provided by BeautifulSoup to parse the HTML content of the response object. Once the parsing is complete, a new object called "soup" is created, which represents the parsed HTML document.
In [3]: In this code, the BeautifulSoup library searches for the first HTML table element that has a class attribute of "wikitable sortable" within the parsed HTML document which is stored in the "soup" variable. Then using the "find_all" method, extract all of the "tr" elements as we can see in Figure-1.
In [4]: Here we used a nested list comprehension feature to extract data from an HTML table.
The first line of code "header = [th.text.strip() for 'th' in rows[0].find_all("th")]" creates a list of column headers for the HTML table. This line extracts the text content of each "th" element (i.e., table header cell) within the first row of the table (i.e., rows[0]). The ".text.strip()" method is used to remove any extra whitespace or newlines from the header text. The resulting list of column headers is assigned to a variable called "header".
The second line of code "data = [[td.text.strip() for 'td' in row.find_all("td")] for row in rows[1:]]" creates a list of lists that contains the data from each row and column of the HTML table. This line uses a nested list comprehension to iterate over each row in the "rows" list (excluding the first row, which contains the column headers). For each row, the code extracts the text content of each "td" element (i.e., table data cell) and stores it in a list.
The resulting list of data rows is a list of lists, with each inner list representing a single row of the HTML table. This list of data is assigned to a variable called "data".
In [5]: We create a pandas DataFrame from the extracted data, using the header list as column names. By passing 'data' and 'header' as parameters to the "pd.DataFrame" function, the code creates a new DataFrame object 'df' with the specified column names and data.
In [6]: Using the 'to_csv()' method of the pandas DataFrame, saved the extracted data from the Wikipedia page in a CSV file, "largest_banks.csv". Passed the "index=False" argument to exclude the index column from the CSV file.
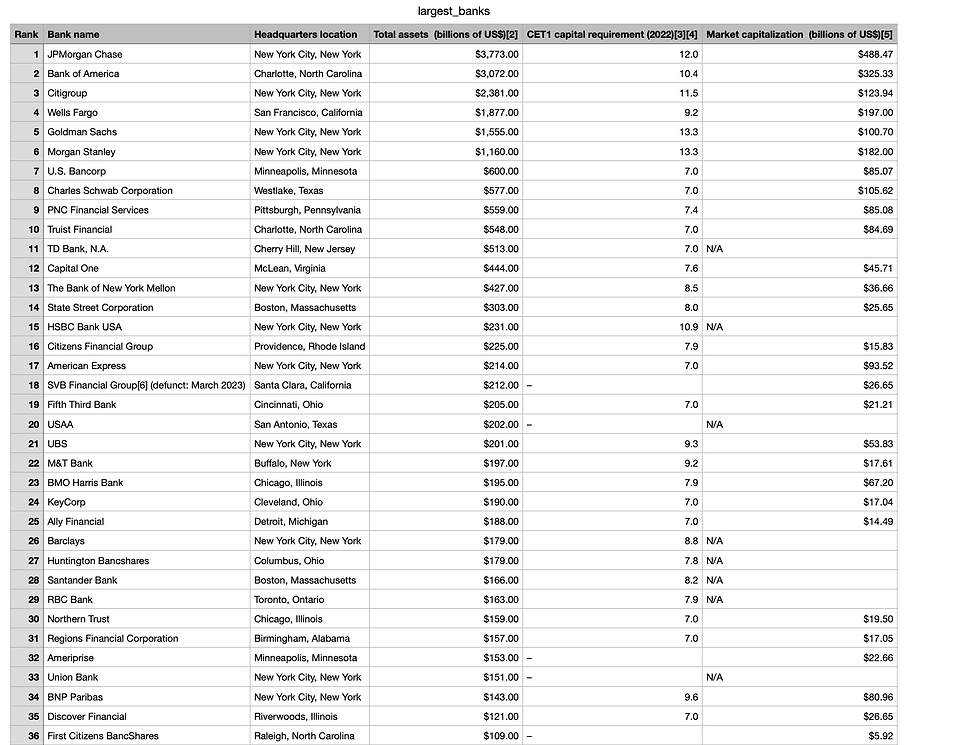
Figure-3: Scraped data stored in largest_banks.csv file
In conclusion, web scraping can be useful for a wide range of applications, from market research and data analysis to price comparison and E-mail address gathering. Still, it's important to note that web scraping can sometimes be a controversial practice, as it may violate website terms of service or copyright laws. It's important to check the legal implications and ethical considerations before engaging in any web scraping activities. I hope this blog was informative and added value to your knowledge. Happy web scraping.