_edited_edited.png)
By Archana Gore
Customized locators are created to handle specific scenarios where the default locators
(id, name, class name, tag name, etc.) may not be sufficient or when you want to enhance code readability and maintainability.
Customized locators can be especially useful when working with complex web applications that have unique attributes or patterns in their element structure.

In this blog, we will be seeing customized locators.
Locating elements by using CSS Selector
CSS means Cascading Style Sheets. CSS is used to make a webpage more attractive and presentable. It allows developers to define styles for HTML elements, including fonts, borders, colors, layout, background, spacing, and more. By using CSS developers can create a web more efficient, maintainable, and easily accessible.
CSS Selectors allow testers to locate a specific element and perform various actions on it, such as clicking, entering text, verifying content, etc. It also allows testers to target unique elements, select groups of elements, handle dynamic elements, verify element states, etc.
Here are some common types of CSS Selectors:
I will be using https://admin-demo.nopcommerce.com/login?ReturnUrl=%2Fadmin%2F for CSS selectors demo purposes.
1. Tag and ID: selects elements based on their tag and ID attribute. Tag and ID attribute is separated by using the “#” sign.
Note: if “id” is available then you can locate using the “ID” locator. CSS Selector is optional.
Syntax: #id OR tag#id
Ex. #Email OR input#Email
Ex. I want to locate the Email text area and send a text



OR

“admin@yourstore.com” is the text entered into the text area using the “id” CSS Selector.
2. Tag and class name: Select elements based on their tag and class name. Tag and class attribute is separated by the ”.” (dot).
Syntax: .class OR tag.class
Ex. .form_group OR div.form_group
Note: compound classes are not permitted. As shown below screenshot, if you see a space between the class attribute value then choose any one. The whole value won’t match.

Ex. I want to locate the Password text area and send a text
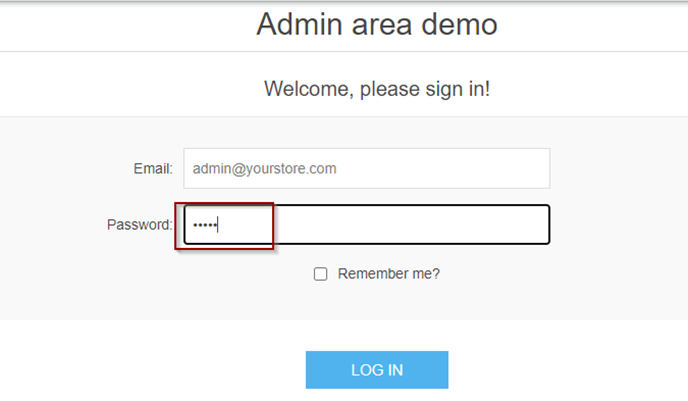

OR

Entering text into the “Password” text area using the “class” CSS Selector.
3. Tag and attribute: selects elements based on their tag and attribute. When there is no id, name, or class available then go with tag and attribute.
Syntax: [attribute=’value’] OR tag name[attribute=’value’]
Ex. [type='button'] OR Input[type='button']
Ex. want to locate and click on the “Log In” button


OR

Locating and clicking on the “LOG IN” button with the help of the “attribute” CSS Selector.
4. Tag, class, and attribute: Select elements based on their tag name, class name, and attribute.
Syntax: .class[attribute=’value’] OR tag.class[attribute=’value’]
Ex. .form-control[placeholder=’Search’] OR input.form-control[placeholder=’Search’]
Ex. want to locate and enter text into the Search box.
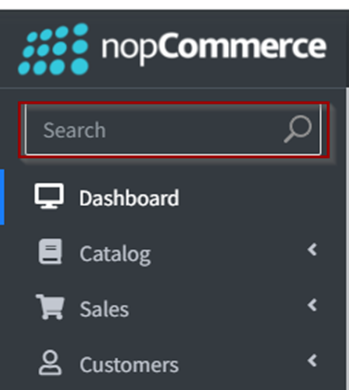
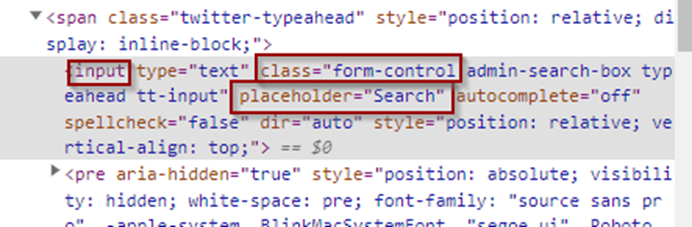

OR

Here entering the text “ORDERS” into the search box with the help of the tag, class, and attribute CSS Selector.
Locating Elements by using XPath
What is XPath?
XML Path Language, or XPath, is a query language designed for selecting nodes from XML documents. In Selenium, XPath is utilized to locate elements based on their attributes, tags, text content, or their relationship with other elements in the HTML structure. There are two types of XPath: Absolute XPath and Relative XPath.
Types of XPath:
1. Absolute XPath: Absolute XPath is an XPath expression that starts with the root node of the XML document or the HTML page to the target element. It describes the entire hierarchical structure of the elements from the root node to the target element.
Ex. Consider the below screenshot
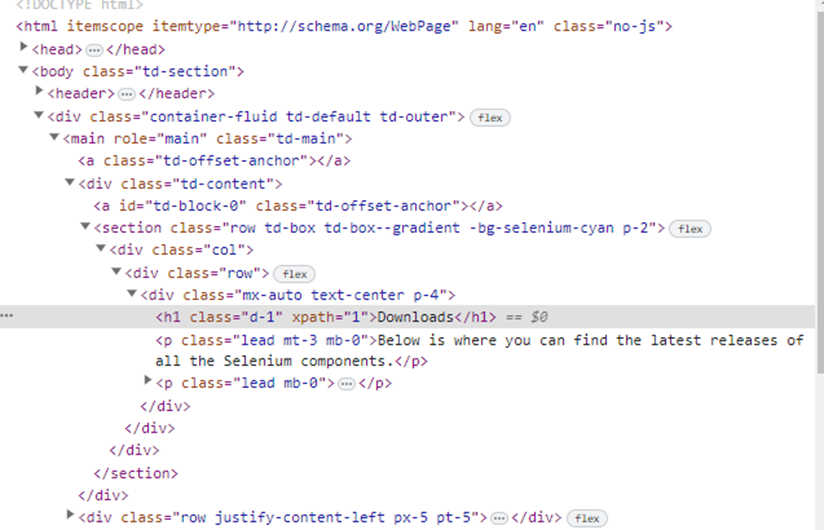
XPath for the “<h1>” element in this HTML would be:
/html[1]/body[1]/div[1]/main[1]/div[1]/section[1]/div[1]/div[1]/div[1]/h1[1]
The actual element is present in the “<h1>” tag, the rest of the part of the XPath is the path to that element.
Absolute XPath is not advisable due to the following reasons.
1. Absolute XPath expressions tend to be long, complex, and hard to read, understand and maintain.
2. Since they traverse from the root node to the target root, they may take longer processing time.
3. The absolute XPath may no longer work if the application or website is redesigned or the HTML structure changes.
Instead, it is recommended to use Relative XPath.
2. Relative XPath: Relative XPath is an XPath expression that starts from a specific element in the HTML document and describes the path to the target element based on its relationship to that starting element. Relative XPath expressions are not dependent on the entire HTML structure but on the context of the element being located.
Ex. Consider the below screenshot

XPath for the “<h1>” element in this HTML would be: //h1[text()='Downloads']
“//” (forward double slash) at the beginning of the XPath denotes selecting any element in the document regardless of its location. Here, “//h1” will select all “<h1>” elements in the document no matter where they are nested. Or we can simply say “//” skips all other nodes and start selecting the “<h1> “ element.
Here, XPath for the “<h1>” element would also be: //h1
But to make it more robust and less prone to breaking if the structure of the XML or HTML document changes, writing its text that is “Downloads”. Also, here other attributes are not available that’s why using text().
Why do we need to master various XPath Syntaxes?
Below are various reasons:
· We may not be able to locate some elements using their ID or name as some elements do not have unique attributes (id, name).
· Some attributes change dynamically.
· There could be some elements without having attributes too.
We need to locate such elements differently than static elements.
What should be considered when choosing XPath?
It is important to consider the following when choosing XPath from the available options:
A good Locator is:
· Unique: When you are locating a single element your XPath should have only one unique element.
· Descriptive: It will be easier to identify the element if it is descriptive.
· Shorter in length: When you have multiple options, a shorter XPath should be selected to make it more readable in your test script.
· Resilient: XPath should be selected in such a way that it remains valid even if changes are made in DOM.
Various XPath syntaxes to locate elements:
XPath provides various syntaxes and expressions to locate elements within XML or HTML documents.
Here are some common XPath syntaxes used to locate elements:
1. Locating elements with a known attribute:
Syntax: //* [@attributeName=’value’]
Ex. let’s locate the Search box in the following screenshot

Here we have four different Xpaths
1. //*[@type=’text’]
2. //*[@name=’search’]
3. //*[@placeholder=’Search’]
4. //*[@class='form-control form-control-lg']
Note: the first Xpath (//*[@type=’text’]) should not be used, even though it is valid. Because it is not unique. There can be multiple elements with type=”text”.
The recommended XPath is “//*[@name=’search’]” since the “name” is a unique attribute.
2. Locating elements with tagName and an attribute:
Syntax: //tagName[@attributeName=’value’]
Ex. let’s locate the Search box in the following screenshot

Examples:
1. //input[@name=’search’]
2. //input[@placeholder=’Search’]
3. //input[@class='form-control form-control-lg']
3. Locating elements with static visible text(Exact match)
The following syntax is used when locating elements with exact visible text within the opening and closing tags (inner text).
Syntax: //tagName[text()=’exact visible text’]
OR //*[text()=’exact visible text’]
Let’s locate the “Login” heading consider the screenshot

Examples:
1. //h5[text()='Login']
2. //*[text()='Login']
Note: the inner text is case-sensitive.
Locating elements by visible text is not advisable when:
1. Testing a multilingual application
2. Same text is appearing in more than one places
4. Locating elements when part of the visible text is static (partial match)
Syntax:
//tagName[contains(text(), ‘substring’])
//*[contains(text(), ‘substring’])
//tagName[contains(.,’substring’)]
Let’s consider below screenshot:

Examples:
//h1[contains(text(),'Selenium automates')]
//*[contains(text(),'Selenium automates')]
//h1[contains(.,'Selenium automates')]
5. Locating elements with Dynamic attribute values
Sometimes, elements are dynamic and their attribute values constantly change. As a result, we must locate these elements using a different approach.
Syntax:
//tagName[contains(@attribute,’substring of the value’)]
//*[contains(@attribute,’substring of the value’)]
//tagName[starts-with(@attribute,’prefix of the value’)]
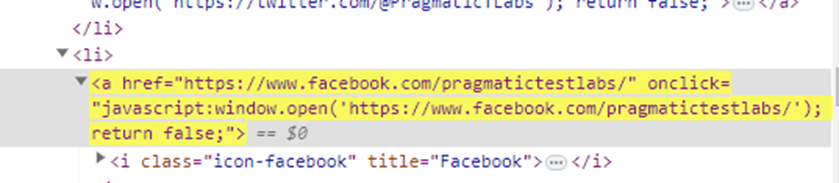
Examples:
1. //a[contains(@href,'pragmatic')]
2. //*[contains(@href,'pragmatic')]
3. //a[starts-with(@href,'http')]
6. Locating elements when the prefix of the inner text is static
We can locate elements when part of the inner text is static.
Syntax:
//tagName[starts-with(text(),’prefix of inner text’)]
OR //*[starts-with(text(),’prefix of inner text’)]

Examples:
//h1[starts-with(text(),'Selenium')]
//*[starts-with(text(),'Selenium au')]
7. Locating elements with multiple attributes
Sometimes it may not be possible to locate elements with a single attribute uniquely as there could be more than one element available with a given attribute. In such cases, we have to locate it using a combination of multiple attributes.
Syntax:
//tagName[@attributeName1=’value1’][@attributeName2=’value2’]……… [@attributeNameN=’valueN’]
OR //*[@attributeName1=’value1’][@attributeName2=’value2’]……… [@attributeNameN=’valueN’]
OR //tagName[@attributeName1=’value1’ and @attributeName2=’value2’]
OR //*[@attributeName1=’value1’ and @attributeName2=’value2’]
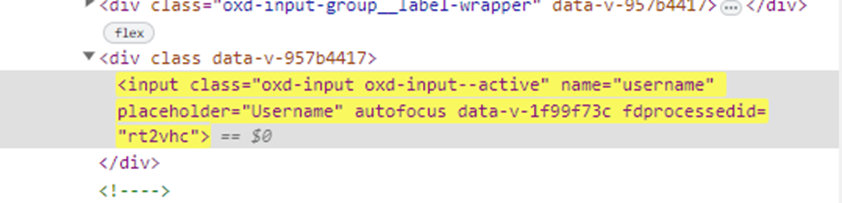
Examples:
1. //*[@name='username'][@placeholder='Username'][@class='oxd-input oxd-input--active']
2. //input[@name='username'][@placeholder='Username'][@class='oxd-input oxd-input--active']
3. //input[@name='username' and @placeholder='Username']
4. //*[@name='username' and @placeholder='Username']
Summary:
CSS Selectors:
1. Tag and id: #id OR tag#id
2. Tag and class: .class OR tag.class
3. Tag and attribute: [attribute=’value’] OR tag name[attribute=’value’]
4. Tag, class and attribute: .class[attribute=’value’] OR tag.class[attribute=’value’]
XPath:
1. Locating elements by id:
Syntax: //*[@id=’attribute value’]
Example: //*[@id=’username’] (Selects the element with the id ‘username’)
2. Locating elements by tag name:
Syntax: //tag name
Example: //h1 (selects all <h1> elements on the page.)
3. Locating elements by class name:
Syntax: //*[contains(@class,’class attribute value’)]
Example: //*[contains(@class,’btn’)] (selects elements with the class containing “btn”)
4. Locating elements by attribute:
Syntax: //*[@attribute=’value’]
Example: //*[@class=’my-class’] (selects elements with class “my-class”)
5. Locating Elements by Attribute Partial Value:
Syntax: //*[contains(@attribute, 'value')]
Example: //*[contains(@href, 'example.com')] (Selects elements with href containing "example.com")
6. Locating Elements by Text Content:
Syntax: //*[text()='desired-text']
Example: //*[text()='Click Here'] (Selects elements with the exact text "Click Here")
7. Locating Elements with Multiple Conditions:
Syntax: //tag name[@attribute='value' and @attribute2='value2']
Example: //input[@type='text' and @name='username'] (Selects an input element with type="text" and name="username")
8. Locating Elements by Index:
Syntax: (//tag name)[index]
Example: (//a)[3] (Selects the third <a> element on the page)
These are some examples of XPath syntax used for finding elements. XPath is a versatile language that enables complex searches, and you can combine different expressions to locate specific elements within a document. It is crucial to make sure that your expressions are precise enough to target the desired elements accurately and can adapt to any changes in the document's structure when using XPath to locate elements.
Happy Learning!!!