_edited_edited.png)

A hyperparameter is a parameter that controls the learning process of the machine learning algorithm. Hyperparameter Tuning is choosing the best set of hyperparameters that gives the maximum performance for the learning model.
Model Parameters
In a machine learning model, training data is used to learn the weights of the model. These weights are the Model parameters.
Example: In a linear regression model, the model is trained to produce the accurate prediction of the function y=mx + b, where m is slope and b is intercept.
Here m and b are the model parameters whose best values are chosen by training the model with data. So, model parameters are parameters chosen by the machine learning algorithm to adjust to the data.
Hyperparameters
Hyperparameters are the model setting values that a learning algorithm uses to estimate the model parameters. These values are not learned from training data but are fixed at the time of model definition only i.e., before the beginning the actual training process. These parameters are important because these values determine properties of the model such as complexity, speed of learning etc.
Example: In Decision Tree classifier, the number of estimators and maximum depth of the tree are some of the hyperparameters that are set before the training process, values of which determines the performance of the model.
Hyperparameters are set before training the model whereas model parameters are learned during the training phase.
Hyperparameter Tuning
Selecting the correct combination of hyperparameters to achieve maximum performance is called hyperparameter tuning. Scikit-Learn sets some default values for the hyperparameters of a model, but these values do not give optimum results. The best values are usually determined by trial-and-error methods. Trying out different combinations and evaluating the performance each time results in determining the best hyperparameters.
However, evaluating the combination only on training data can lead to overfitting, i.e., the model tries to fit training data very well that it cannot generalize to the new data. To overcome this problem, cross validation is used where the dataset is divided into training set, Validation set and Test set.

The most commonly used cross validation technique is the K-Fold cross validation, where training set is divided into K number of subsets called folds. The model is iteratively fit K-times each time using data of K-1 folds for training and validating on the Kth fold.
Example: Following is the dataset split for 5-Fold Cross Validation.

For hyper parameter tuning in K-fold cross validation, many combinations of the hyper parameter values are chosen each time to perform K iterations. Then a best combination is selected and tested. So, for a 5-Fold Cross validation to tune 5 parameters each tested with 5 values, 15625 iterations are involved. But as this is a tedious process, Scikit-Learn implements some methods to tune the model with K-Fold CV. In this blog we will see two popular methods -Grid search CV and Random search CV.
Grid-Search CV
This is one of the hyper parameter tuning method. In this method, a grid of important hyperparameter values is passed and the model is evaluated for each and every combination. The set of hyperparameters which gives highest accuracy is considered as best.
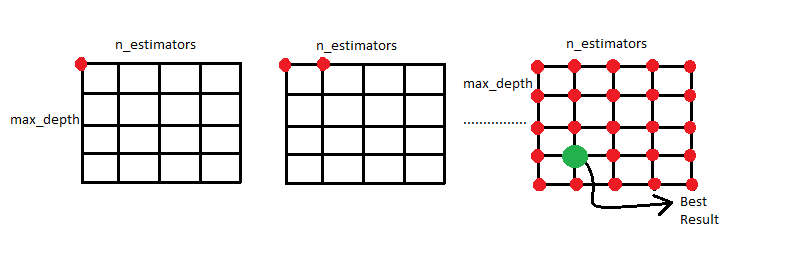
Example: Taking Boston house price dataset to check accuracy of Random Forest Regression model and tuning hyperparameters-number of estimators and max depth of the tree to find the best value.
First load boston data and split into train and test sets.
import numpy as np
import pandas as pd
#load Boston data from sklearn
from sklearn.datasets import load_boston
boston = load_boston()
#splitting data into train and test
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(boston.data,boston.target,test_size=0.3)Apply Random Forest Regressor model with n_estimators of 5 and max_depth of 3
from sklearn import ensemble
dt=ensemble.RandomForestRegressor(n_estimators=5,max_depth=3)
dt.fit(x_train,y_train)
dt.score(x_test,y_test)Resulted score is 0.8378772944305637.
This shows that the model is overfitting the data. So, applying cross-validation with 10 folds:
from sklearn.model_selection import cross_val_score
scores1 = cross_val_score(ensemble.RandomForestRegressor(n_estimators=5,max_depth=3),x_train,y_train,cv=10)
np.average(scores1)Resulted score is 0.6868151359725105.
This score can be improved with hyperparameter tuning using Gridsearch CV. For this, a list of dictionaries of the list of hyperparameter values is passed. Then model is evaluated on every combination of each list of values to find the best one.
Applying Grid Search to tune n_estimators, max_depth and max_features
model=ensemble.RandomForestRegressor()
from sklearn.model_selection import GridSearchCV
parameters=[{'n_estimators':[20,30,40,60,100], 'max_depth':
[5,10,15,20]},
{'n_estimators':[20,30,40,60,100], 'max_depth':
[5,10,15,20],'max_features':[2,5,8]}]
grid_search = GridSearchCV(estimator=model,
param_grid=parameters,
cv=10,
n_jobs=-1)
grid = grid_search.fit(x_train,y_train)
grid.best_score_The resulting best score is 0.8857281015151924. To find the parameters which resulted in the best score, below command is given:
grid.best_params_Result is {'max_depth': 10, 'max_features': 5, 'n_estimators': 60}
So, when number of estimators is 60, max_features is 5 and max_depth of tree is 10 then Cross validation of 10 folds is giving best performance for a Random Forest model.
In Grid Search, when the dimension of the dataset increases then evaluating number of parameters grow exponentially. So, this method performs inefficiently. The solution for this problem is Random Search cross validation.
Random Search CV
Random search cross validation would pick random combinations among the range of values specified for hyperparameters. Unlike Grid search CV, this wont test sequentially all the combinations. Here, we specify the number of random combinations that are to be tested on the model.

In Random search CV, the best combination can not be identified because all the combinations are not tested. But the advantage is we can test a broad range of values for hyperparameters within the same computation time as grid search CV.
Below is the implementation of Random search for the above example of Boston Housing prices dataset.
from sklearn.model_selection import RandomizedSearchCV
model=ensemble.RandomForestRegressor()
param_grid=[{'n_estimators':[20,30,40,60,100], 'max_depth':[5,10,15,20]
},{'n_estimators':[20,30,40,60,100], 'max_depth':[5,10,15,20]
,'max_features':[2,5,8]}]
rnd_search = RandomizedSearchCV(model, param_grid, cv=10,
return_train_score=True)
rnd_search.fit(x_train,y_train)
rnd_search.best_score_
The result is 0.8722396751562318. To find the parameters which resulted in the best score, below command is given:
rnd_search.best_params_The Result is {'n_estimators': 40, 'max_depth': 20}. We can observe that the value is different from the Gridsearch CV.
In the above example though we don’t search all the parameters, we are trying broad range of values and computation time is very less.
Conclusion
Setting the correct combination of hyperparameters is the only way to extract the maximum performance out of models. There is a tradeoff to make while selecting between the Grid search and Random search in terms of finding best parameters vs computation time. A simple solution could be to start with a random search to reduce the parameter space and then do a grid search to select the optimal values within this space.