_edited_edited.png)
Use Case - Read company name as displayed in the login logo screen from LMS UI application.
In UI functional testing we try to cover all the aspects of web pages including presence and state of web elements. For any Login page, we can check if the logo is present but what if we want to test the text inside logo for company's name. With the help of free tools we can automate this task.
Since Selenium cannot extract text from images, we are using an OCR tool for this task.
Approach – Use Tesseract to extract text from the following image.

What is Tesseract - Tesseract is an optical character recognition engine for various operating systems. It is an open-source free tool. This AI based engine can detect more than 100 languages and can be trained to recognize other languages.
It supports various output formats, including plain text, HTML, PDF and more. It also has Unicode (UTF-8) support.
Latest version has added a new neural net (LSTM) based OCR engine which is focused on line recognition but also still supports the legacy Tesseract OCR engine which works by recognizing character patterns.
How OCR works?
1. Pre-process image data, for example: convert to gray scale, smooth, de-skew, filter.
2. Detect lines, words and characters.
3. Produce ranked list of candidate characters based on trained data set. (here the setDataPath() method is used for setting path of trainer data)
4. Post process recognized characters, choose best characters based on confidence from previous step and language data. Language data includes dictionary, grammar rules, etc.

Setup and Implementation:
Step1 : Download Tesseract installer for Windows
Here is the alternative installer path Tesseract installer with latest versions.
Step2: Create Maven java project and Add tess4j to pom.xml
To integrate Tesseract OCR with Java, we need to use the Tesseract API for Java, typically known as Tess4J
<dependency>
<groupId>net.sourceforge.tess4j</groupId>
<artifactId>tess4j</artifactId>
<version>5.11.0</version>
</dependency>
Step3: Download language train data from Github
Step4: Set the environment variable to use Tessdata downloaded in the above step

Step5: Capture the image
Launch the webpage using Selenium TestNG framework with Testrunner file
Locate web element image containing text using Selenium code
Get screenshot of the image
Use Tess4J to perform OCR.
Compare recognized text with expected text value.
Step6: Handling multiple languages
Tesseract OCR supports over 100 languages. To perform OCR with a different language, simply set the language on the Tesseract instance −
instance.setLanguage("fra"); // for French
Then, call doOCR() as usual −
try {
String result = instance.doOCR(imageFile);
System.out.println(result);
} catch (TesseractException e) {
System.err.println(e.getMessage());
}
Code snippets from the Maven project
Feature File
@tag1
Scenario: Verify admin is able to land on home page
Given Admin launch the browser for login page
When Admin gives the correct LMS portal URL for login page
Then Admin should land on the home page
@tag2
Scenario: Verify company name
Given Admin is in Home Page
Then Admin should see company name below the app name on login page
Step Definition
@When("Admin gives the correct LMS portal URL for login page")
public void admin_gives_the_correct_lms_portal_url_for_login_page() {
Driverfactory.getDriver().get("https://lms.....URL");
}
@Then("Admin should see company name below the app name on login page")
public void admin_should_see_company_name_below_the_app_name_on_login_page()
throws IOException, TesseractException {
loginHomePage.companyNameValidation();
}
Code Snippet for OCR
public void companyNameValidation() throws TesseractException, IOException {
// Locate the image element
//****************************************************************
WebElement imageElement = webDriver.findElement(By.xpath("//img[@src='assets/img/LMS-logo.jpg']"));
//Take screenshot of the image
//****************************************************************
File src = imageElement.getScreenshotAs(OutputType.FILE);
String filePath = System.getProperty("user.dir") + "\\image.png";
FileHandler.copy(src, new File(filePath));
// Instantiating the Tesseract class which is used to perform OCR
//****************************************************************
ITesseract tesseract = new Tesseract();
// Set Tesseract-OCR tessdata path which you installed in Step 1
//****************************************************************
tesseract.setDatapath("C:\\Program Files\\Tesseract-OCR\\tessdata");
// Performing OCR on the image and storing result in string
//****************************************************************
String recognizedText = tesseract.doOCR(new File(filePath));
//Removing newline characters from the above string
//****************************************************************
recognizedText = recognizedText.replaceAll("\\n", "");
//Removing extra characters from the above string
//****************************************************************
recognizedText = recognizedText.replaceAll("= ", "");
// Compare the recognized text with the expected text
//****************************************************************
String expectedText = "LMS - Learning Management Systemes NumpyNinja";
//Assertion
//****************************************************************
if (recognizedText.equals(expectedText)) {
System.out.println("OCR test successful.");
}
else {
System.out.println("OCR test failed.\n Expected text: " + expectedText + "\n Recognized text: " + recognizedText);
}
}
Additional Use Cases:
Handling and automating captchas for website logins.
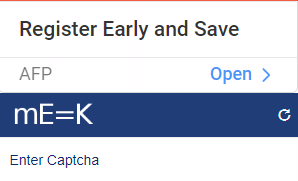
The main purpose of a CAPTCHA (Completely Automated Public Turing test to tell Computers and Humans Apart) is to prevent automated bots from accessing a website or service, ensuring that only humans can pass through.
Text based captcha is the most common type of CAPTCHA. It involves the use of distorted or obscured text that a user must read and type into a text box. The distortion is meant to prevent optical character recognition (OCR) software from being able to read the text. Tesseract can be used to read and enter text based captcha values.
Tesseract, can recognize the characters within a CAPTCHA image, even if the text is distorted or obscured. However, against more complex CAPTCHAs, such as those with overlapping characters or additional noise, OCR might not be as effective.
Handling barcodes

Additional resources:
Challenges with Tesseract OCR
Quality of Input Images: The accuracy of OCR heavily depends on the quality of the input images. Poorly scanned or low-resolution images may lead to incorrect or incomplete text recognition.
Font Styles and Variations: Different fonts, font sizes, and styles (bold, italic, etc.) can impact OCR accuracy.
Language Support: Tess4J supports multiple languages, but some languages may have better accuracy than others.
Character Segmentation Errors: Tess4J may misinterpret characters if they are too close together or touching.
Noise and Artifacts: Noise, artifacts, or background patterns in the image can confuse the OCR engine.
Orientation and Rotation: If the text is rotated or skewed, Tess4J may struggle to recognize it correctly.
Handwriting and Hand-Printed Text: Tess4J is primarily designed for printed text. Handwriting or stylized fonts pose challenges.
Layout and Structure: Complex layouts (tables, columns, headers, footers) can confuse the OCR engine, leading to incorrect text extraction.
Performance and Speed: OCR can be resource-intensive, especially for large documents or high-resolution images.
Handling Special Characters and Symbols: Tess4J may struggle with special characters, symbols, or non-standard punctuation.
Alternatives to Tesseract
Google Cloud Vision API, and Microsoft Azure Computer Vision.
Happy learning ninjas!!!